
HONOR تقدم تقنيات متقدمة للتعرف على الصوت مع إطلاق هاتفها الرائد الجديد Magic V5
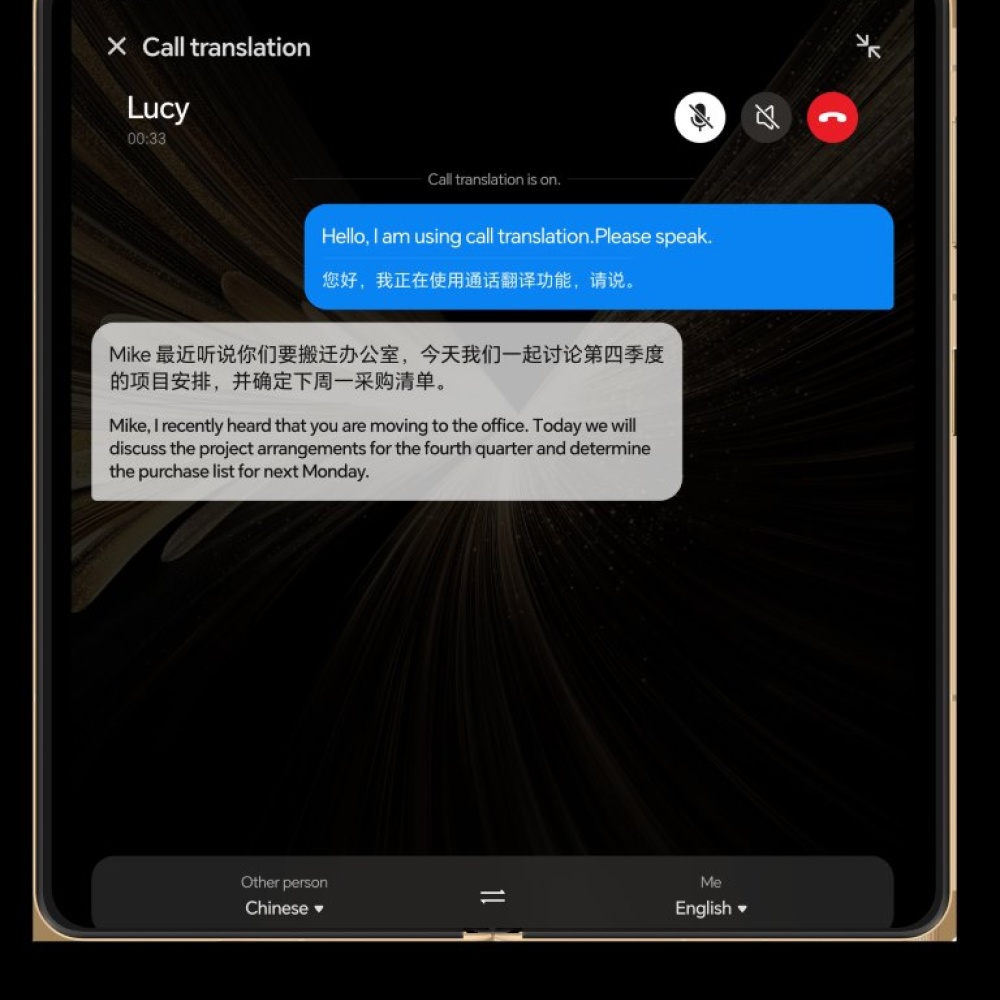
أعلنت HONOR، العلامة التجارية الرائدة عالميًا في مجال أنظمة الأجهزة الذكية المعززة بالذكاء الاصطناعي، عن إطلاق أول نموذج لغوي صوتي كبير يعمل على الجهاز ضمن الإصدارات الدولية لهاتف HONOR Magic V5، ما يُعد إنجازًا غير مسبوق في القطاع. ويمثل هذا التقدم نجاحًا في التغلب على تحديات تقنية رئيسية في مجالي التعرف على الكلام المتعدد اللغات والترجمة الفورية على الجهاز، بما في ذلك تحقيق طفرة كبيرة في تقنيات التعرف على الكلام بزمن استجابة منخفض، ونشر النماذج الكبيرة بكفاءة على الأجهزة.
وفي دعم لهذا الإنجاز التقني، تم اعتماد ورقتين بحثيتين ذات صلة في مؤتمر INTERSPEECH 2025، أكبر وأشمل مؤتمر عالمي لعلوم وتكنولوجيا معالجة اللغة المنطوقة.
معالجة معضلة الخصوصية والأداء
تعتمد حلول الترجمة الشائعة حاليًا بشكل كبير على البنية التحتية السحابية، مما يثير مخاوف كبيرة تتعلق بالخصوصية، خاصة في المحادثات الحساسة مثل المكالمات الهاتفية. وبينما تحاول بعض الحلول الموجودة على الأجهزة المتوفرة في السوق معالجة هذه المشكلة، إلا أنها غالبًا ما تقدم تنازلات كبيرة في الأداء، بما في ذلك السرعة والدقة وكفاءة استخدام الذاكرة، نتيجة القيود التقنية لأجهزة الهواتف المحمولة. أما تقنية HONOR الجديدة، فقد تمكنت من تجاوز هذه التحديات بشكل حاسم، حيث توفر تجربة تضاهي أداء السحابة، ولكن مباشرة على الجهاز نفسه، مما يضمن خصوصية قوية إلى جانب أداء فائق.
تحقيق فوائد غير مسبوقة في الاتصال عبر الأجهزة
تُقدم حلول HONOR المبتكرة مجموعة من الفوائد الجوهرية للمستهلكين، من أبرزها الكفاءة العالية في استخدام الذاكرة، حيث تم تقليص استهلاك الذاكرة من 3-4 جيجابايت إلى 800 ميجابايت فقط، ما يوفر نحو 75% من مساحة التخزين. وتشمل هذه التقنية دمج ست حزم لغوية (العربية، الصينية، الإنجليزية، الألمانية، الفرنسية، الإسبانية، والإيطالية)، مما يُغني عن تحميل ست حزم منفصلة بحجم 500 ميجابايت لكل منها، ويوفر ما يقارب 2.78 جيجابايت من المساحة. وتتيح هذه التقنية أيضًا الترجمة الفورية "أثناء التحدث"، في تطور كبير عن الطرق التقليدية التي تتطلب انتظار اكتمال الجملة قبل الترجمة، ما أدى إلى زيادة سرعة الاستنتاج بنسبة 38% وتحسين دقة الترجمة بنسبة 16%.
INTERSPEECH 2025 يسلّط الضوء على أبحاث رائدة ومعتمدة
تناولت الورقة البحثية الأولى، بعنوان "MFLA: Monotonic Finite Look-ahead Attention for Streaming Speech Recognition"، التحدي الجوهري في تحقيق التعرف على الكلام بزمن استجابة منخفض ودقة عالية على الأجهزة. ويبرز في هذا البحث دمج HONOR المبتكر لمتنبئ يعتمد على آلية التكامل والإطلاق المستمر (CIF) مع استراتيجية Wait-k. وبينما تُحقق استراتيجية Wait-k أداءً جيدًا في المهام القائمة على الرموز المنفصلة مثل الترجمة الآلية، إلا أن تطبيقها المباشر على التعرف التلقائي على الكلام (ASR) يواجه صعوبات بسبب الطبيعة المستمرة للإشارات الصوتية، مما يؤدي إلى تكاليف حسابية عالية. وقد طوّرت HONOR متنبئًا قائمًا على CIF يقوم بتحويل الإشارات الصوتية المستمرة إلى قرارات حدية منفصلة، وهو ما سمح بنقل هذه الاستراتيجية منخفضة الكمون من مجال النصوص إلى مجال الصوت بنجاح.
أما الورقة الثانية، بعنوان "Novel Parasitic Dual-Scale Modeling for Efficient and Accurate Multilingual Speech Translation"، فقد عالجت التحديات المرتبطة بالاستدلال في الزمن الحقيقي باستخدام نماذج صوتية كبيرة على الأجهزة ذات الموارد المحدودة. وقدمت الورقة، بالتعاون مع جامعة شنغهاي جياو تونغ، استراتيجية تسريع جديدة تعتمد على نموذج طفيلي مزدوج المقياس عبر العينة التخمينية (speculative sampling). ويمكن نشر هذه الاستراتيجية على أجهزة الحافة، حيث حققت زيادة بنسبة 38% في سرعة الاستنتاج دون التأثير على أداء النموذج.
تؤكد HONOR من خلال هذين الإنجازين التزامها الراسخ بدفع حدود الذكاء الاصطناعي على الأجهزة، وفتح آفاق جديدة لتجارب أكثر ذكاءً وخصوصية وسلاسة في التفاعل بين الإنسان والتكنولوجيا.







